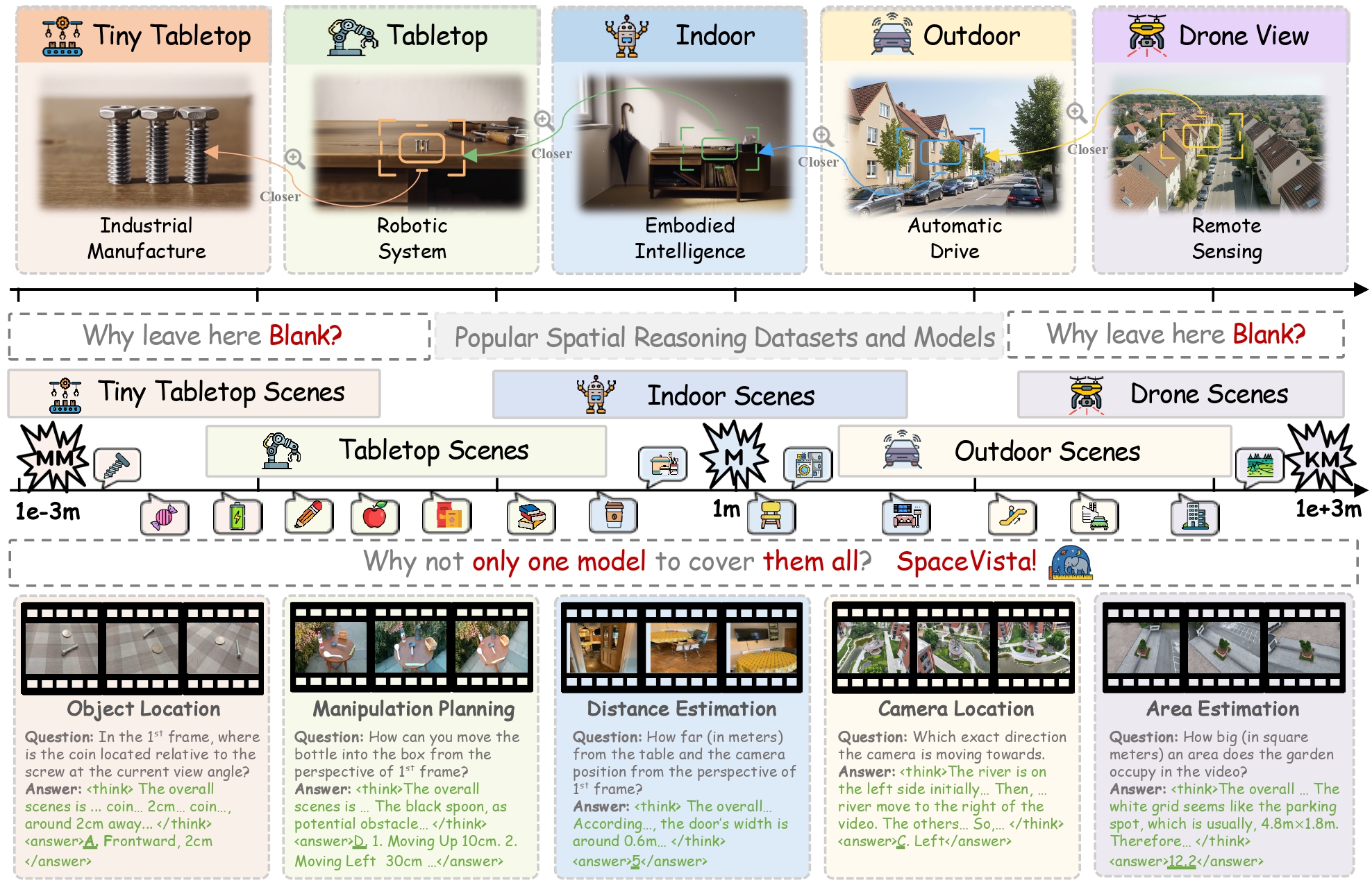

Spatial reasoning is the ability to perceive, interpret, and act across spatial scales, from millimeter-sized components to distant aerial scenes.
All-scale spatial reasoning is fundamental to next-generation intelligent systems and supports diverse applications: mm sensing for advanced manufacturing,
cm and m perception for embodied agents, 10m operation for autonomous driving,
and 100m for drone based sensing.
Despite progress, existing work shows clear limitations in both model design and dataset coverage. Current scene perception research mostly targets indoor scenes,
narrow object classes, and limited spatial ranges, and lacks training paradigms engineered for end to end, cross scale reasoning. SpaceVista addresses
this gap by presenting the first systematic optimization across both data and model dimensions to enable robust, full scene spatial reasoning.
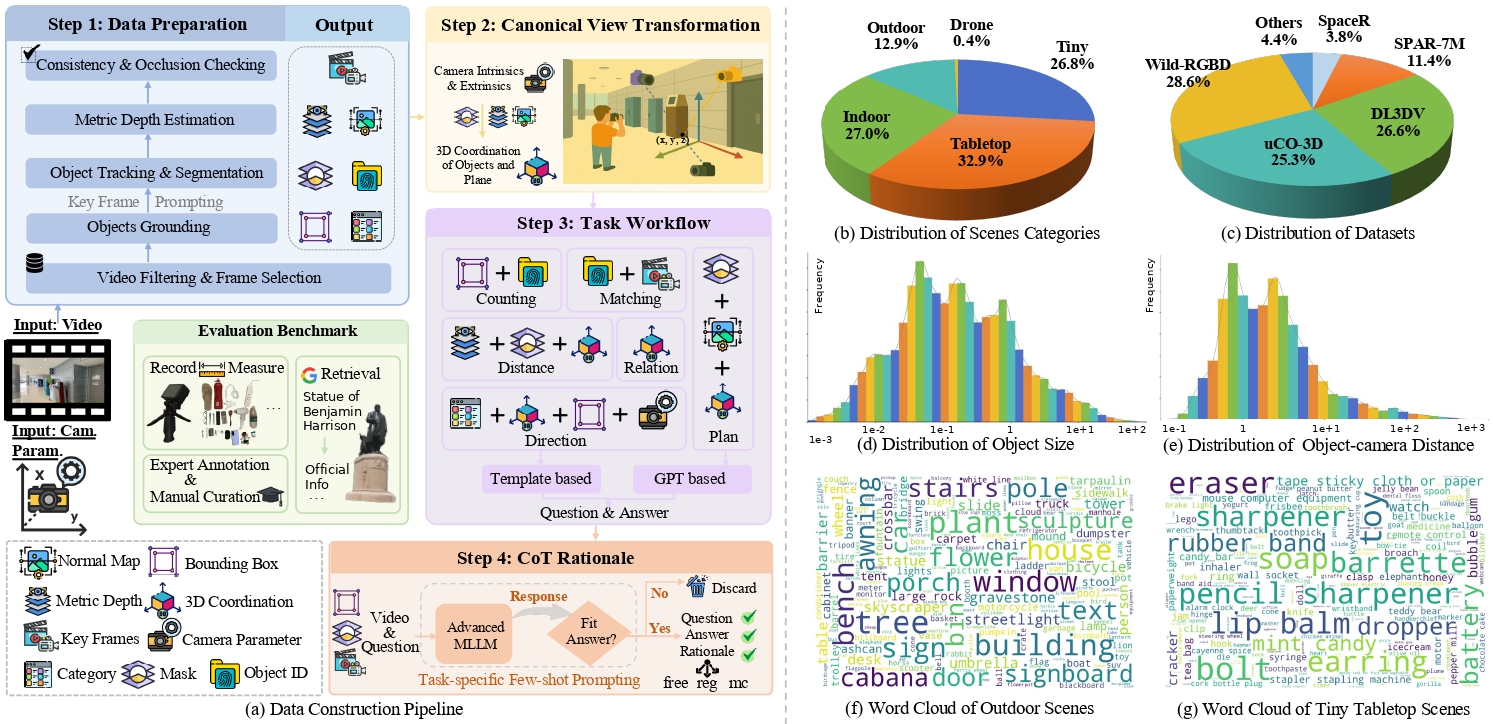
We collect a large number of spatial reasoning videos from both open-source datasets and our own ollected data. Specifically, we select scenes including tabletop, indoor, outdoor, and drone-view scenes, and design 19 types of spatial reasoning tasks covering all-scale from millimeters to kilometers. The dataset contains diverse spatial reasoning question–answer pairs, enriched with semantic, 2D, and 3D annotations.
Although we perform limited manual filtering on open-source data, its suitability for accurately evaluating real-world perception remains uncertain.
To address this, we collect higher-fidelity data comprising two types:
 Why not simply train with all-scale data?
Why not simply train with all-scale data?

Mixing different types of knowledge without distinction hinders, rather than facilitates, the model's reasoning, as shown in the Figure above — a problem known as knowledge conflict. In all-scale reasoning, this conflict appears when similar visual patterns are interpreted differently at different scales.
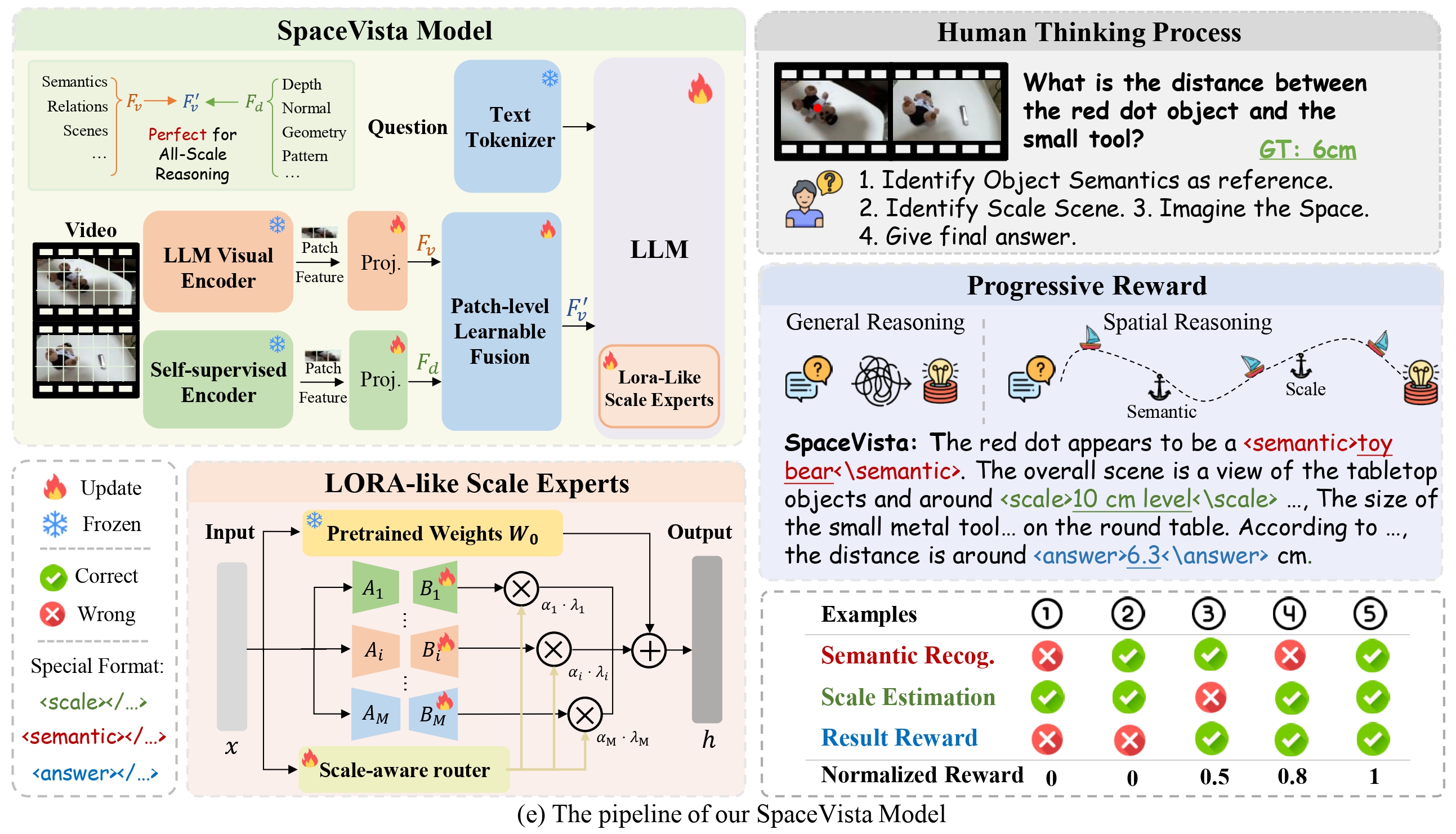
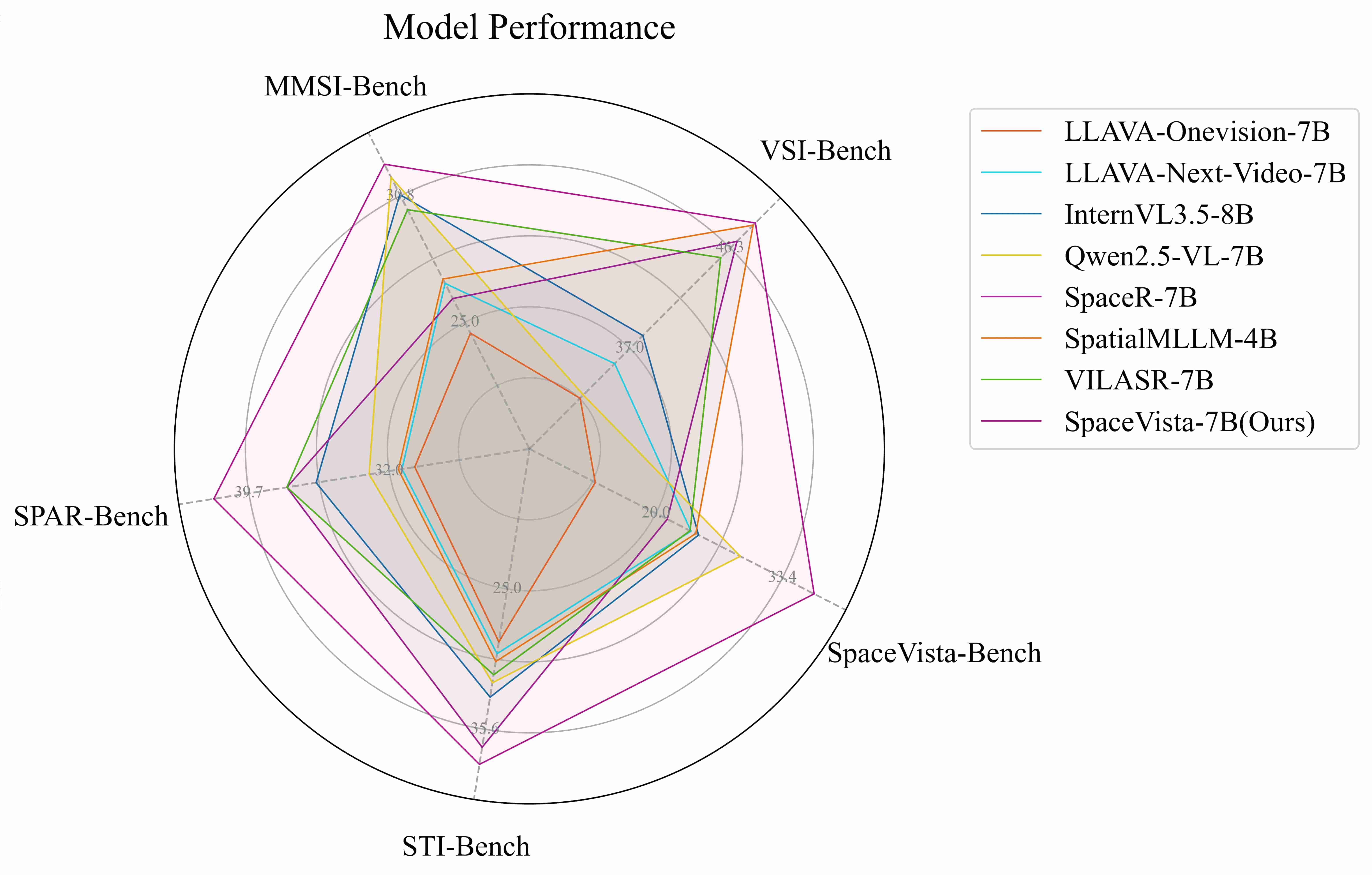
Results overview. SpaceVista-7B achieves comparative improvements across all benchmarks, highlighting its advantages in spatial reasoning tasks. Although models including LLAVA-Onevision-7B also demonstrate competitive performance, SpaceVista-7B consistently shows greater robustness and adaptability across various tasks, thereby solidifying its position as a leading model in the field of spatial reasoning.
Evaluation suite. The comparison across models is conducted on multiple spatial reasoning benchmarks. We conduct a comprehensive evaluation of LLAVA-Onevision-7B, LLAVA-Next-Video-7B, InternVL3.5-8B, Qwen2.5-VL-7B, SpaceR-7B, SpatialMLLM-4-B, VILASR-7B, and our SpaceVista-7B on VSI-Bench, STI-Bench, MMSI-Bench, SPAR-Bench, and SpaceVista-Bench, highlighting the robustness and competitiveness of our model.
 Click the table header to sort in ascending or descending order.
Click the table header to sort in ascending or descending order.| # | Model | Source | Date | Overall | Tiny Tabletop | Tabletop | Indoor | Outdoor |
|---|---|---|---|---|---|---|---|---|
| 3 | GPT-5 🥉 | Link | 2025-08 | 33.7 | 32.2 | 20.3 | 39.0 | 43.0 |
| 8 | GPT-4o | Link | 2024-05 | 26.9 | 21.7 | 13.3 | 34.3 | 38.3 |
| 2 | Gemini-2.5-Pro 🥈 | Link | 2025-06 | 33.8 | 33.0 | 38.7 | 34.5 | 29.0 |
| 11 | Gemini-2.5-Flash | Link | 2025-06 | 24.4 | 20.7 | 30.0 | 19.9 | 26.9 |
| 6 | Claude-Sonnet-4 | Link | 2025-05 | 29.7 | 27.3 | 19.3 | 38.1 | 34.1 |
| 10 | Claude-Opus-4.1 | Link | 2025-08 | 26.4 | 21.7 | 29.5 | 24.3 | 30.0 |
| 5 | Internvl3.5-38B | Link | 2025-08 | 30.7 | 29.3 | 25.2 | 41.2 | 27.0 |
| 10 | Internvl3.5-14B | Link | 2025-08 | 26.4 | 27.7 | 22.3 | 31.3 | 24.3 |
| 4 | Internvl3-78B | Link | 2025-04 | 33.5 | 38.3 | 23.3 | 42.2 | 30.3 |
| 9 | Internvl3-38B | Link | 2025-04 | 26.5 | 18.7 | 14.3 | 34.8 | 38.0 |
| 13 | GLM-4.5V | Link | 2025-08 | 23.3 | 23.0 | 17.8 | 27.3 | 25.2 |
| 14 | GLM-4.1V-Thinking | Link | 2025-07 | 23.1 | 30.7 | 19.3 | 29.0 | 13.3 |
| 10 | Qwen2.5VL-72B | Link | 2025-01 | 26.4 | 27.7 | 20.3 | 29.6 | 28.0 |
| 7 | Qwen2.5VL-32B | Link | 2025-01 | 28.4 | 25.3 | 19.3 | 38.1 | 30.7 |
| 16 | LLAVA-Onevision-72B | Link | 2024-08 | 16.0 | 25.0 | 12.0 | 15.3 | 11.7 |
| 17 | LLAVA-Onevision-7B | Link | 2024-08 | 12.6 | 17.5 | 8.0 | 13.3 | 11.6 |
| 15 | SpaceR | Link | 2025-04 | 21.2 | 12.9 | 17.3 | 34.9 | 19.8 |
| 12 | Spatial-MLLM | Link | 2025-05 | 24.2 | 17.3 | 20.3 | 36.1 | 23.1 |
| 1 | SpaceVista-7B 🥇 | Link | 2025-09 | 36.7 | 33.4 | 37.1 | 42.2 | 34.1 |
Click the scene name to switch the scene preview.
Click the scene name to switch the word cloud.
Click the object name to switch the example.